- モデル更新量を見る
- モデル更新後, 出力がどの程度変化したか
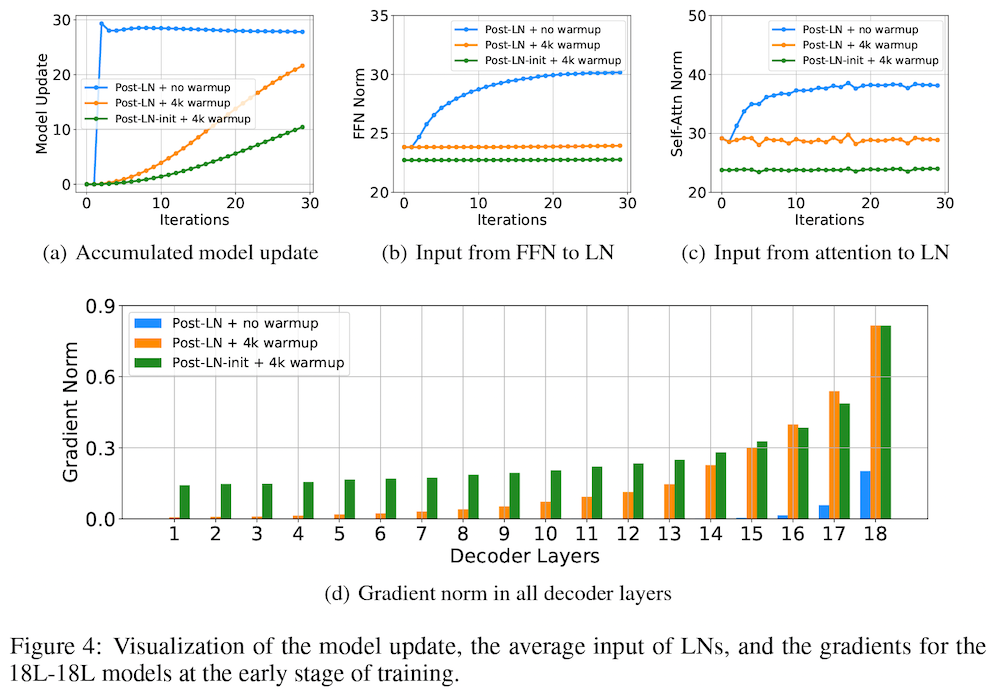
具体的には、まず、18レイヤーの通常の Post-LN トランスフォーマーを訓練させた場合、訓練が不安定であり、検証セットの損失関数の値(ロス)が収束しないことを示しています。このとき、「モデル更新量 (model update)」、すなわち、初期化時に比べて、モデルの更新後に、出力の値がどのぐらい変化したか、に注目すると、上図 Figure 4 の (a) の青線のように、学習の初期に爆発的に増え、その後ほとんど変化していないことが分かります。これは、学習の初期の段階で、モデルのパラメータが局所解に陥ってしまっている可能性を示唆しています。
このとき、レイヤー正規化層の入力の値に注目すると、上図 Figure 4 の (b) の青線のように大きくなっていることが分かります。レイヤー正規化を通る勾配の大きさは、入力の大きさに反比例することが知られている (Xiong et al., 2020) ので、これによって、上図 Figure 4 の (d) の青い棒グラフに示されたように、特に下位のレイヤーにおいて、勾配消失 (vanishing gradient) の問題が起きており、局所解から抜けられなくなっていることが示唆されます。
この問題は、これまで広く採用されている手法である、学習率を徐々に増やしていく「ウォームアップ」によってある程度軽減されることが分かります (上図 Figure 4 のオレンジの線)。また、著者らは、順方向伝播層の出力投影のパラメータを、低位レイヤーに対して小さく初期化する 「Post-LN-init」 と呼ばれる方法を提案し、これによってさらに学習が改善することを示しています
https://ja.stateofaiguides.com/20220308-deepnet-transformer/