- CVPR22
- タスク: KB-VQA
- 質問画像に含まれていない知識を要する質問に回答するタスク
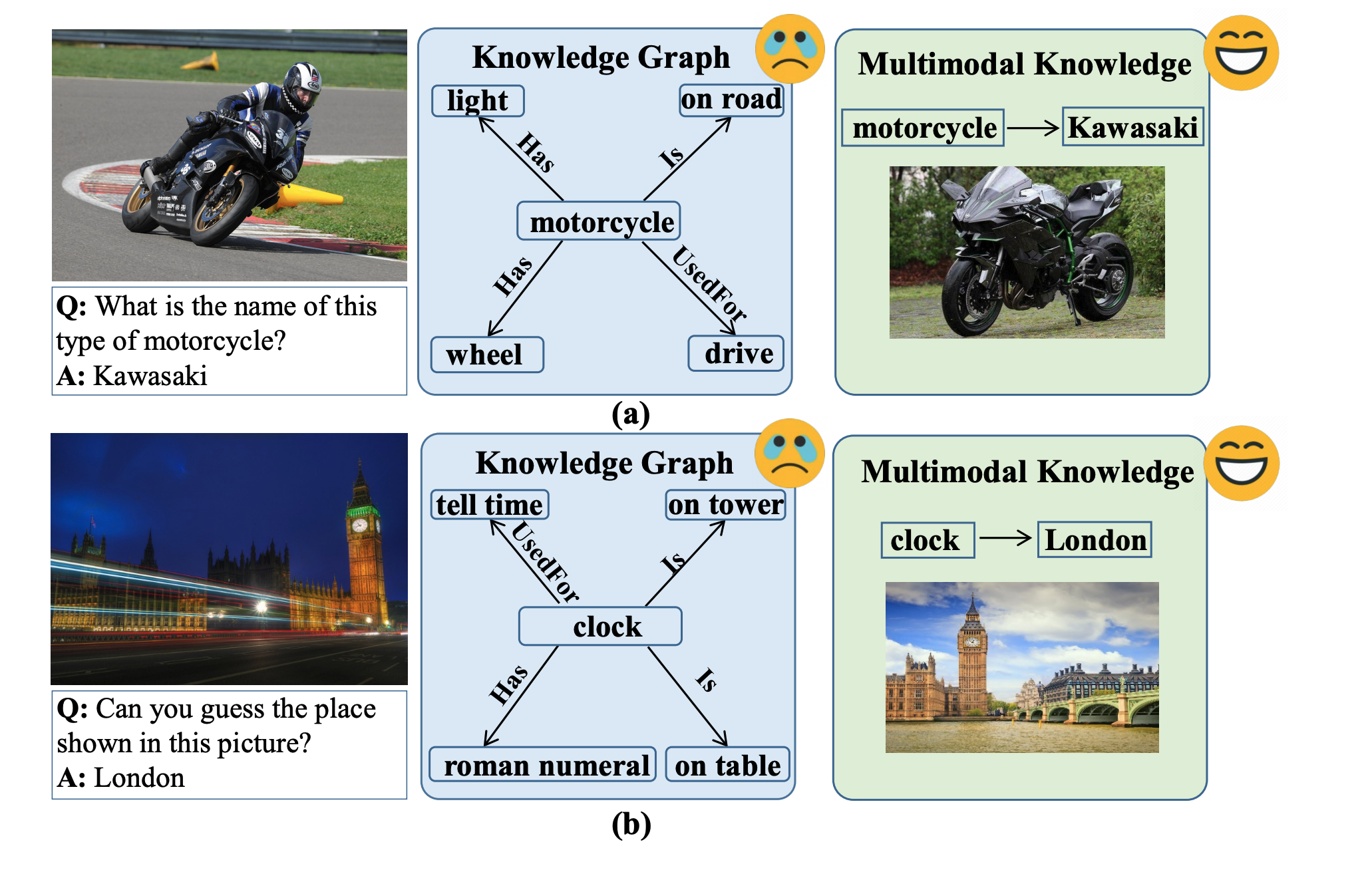
- 例えば, 以下のVQAでは, 外部知識=kawasakiを使わないと回答できない
-
新規性
- 知識グラフの構築は行わない
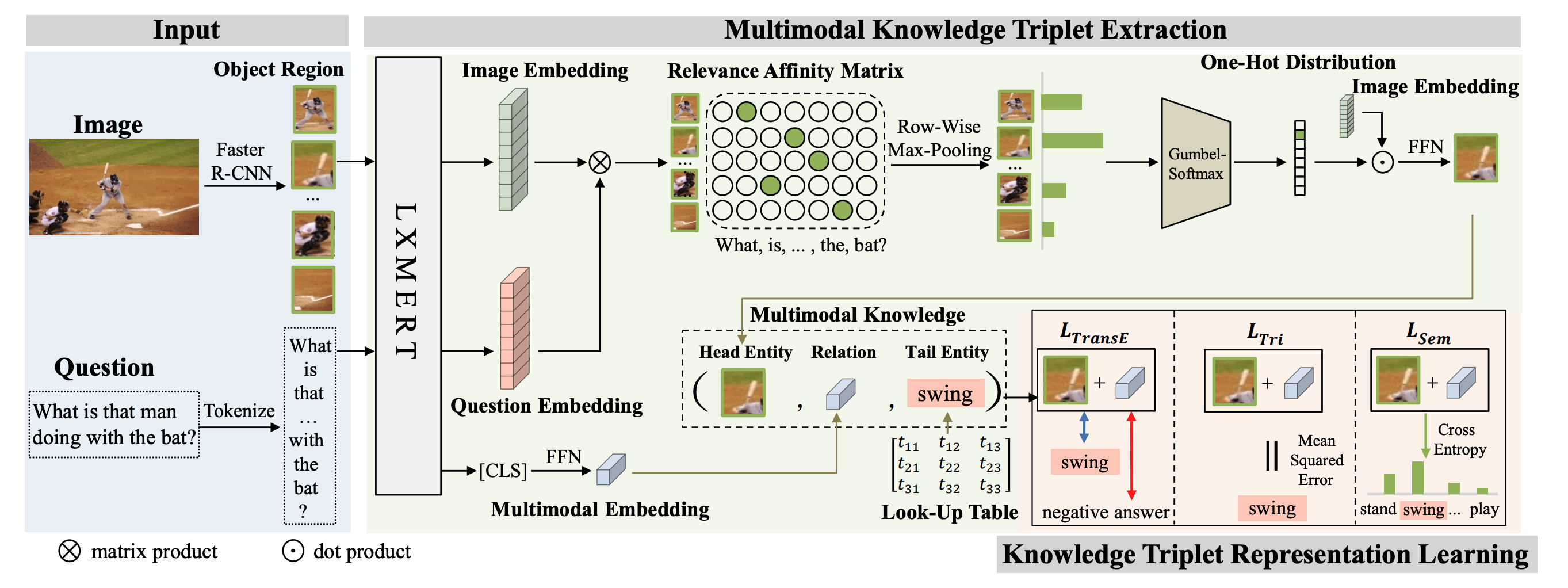
- scene graphを作るのではなく, 画像由来のHead Entity (領域画像)と, 言語由来のTail Entity (後述)について, (entity, relation, entity)のtripletを用いて学習
-
triplet (entity, relation, entity)
-
Head Entity
- Faster-RCNNで抽出した領域画像と質問文をLXMERTにブチこみ, 画像特徴量を得る
- この画像特徴量と質問文のrelevence affinity matrix(スコア行列)を計算し, 親和性の高い領域画像の画像特徴量をHead Entityとする
-
Tail Entity
- 学習時は学習可能パラメタとしてQAのキャプションから学習
- 推論時は知識グラフ (知識DB)からの補完問題として解く
- Tail Entity自体がVQAのanswerとなる
-
relation
-
-
定性的結果
