-
背景
- Instance-wiseな教師なし表現学習 : 加⼯された画像(instance)のペアが同じ元画像に由来するかを識別
- Instance-wiseな⼿法における2つの問題点
- 1- 低次元の特徴だけで識別できるため, 識別はNNにとって簡単なタスク
- → **⾼密度な情報をエンコードしているとは⾔い難い **
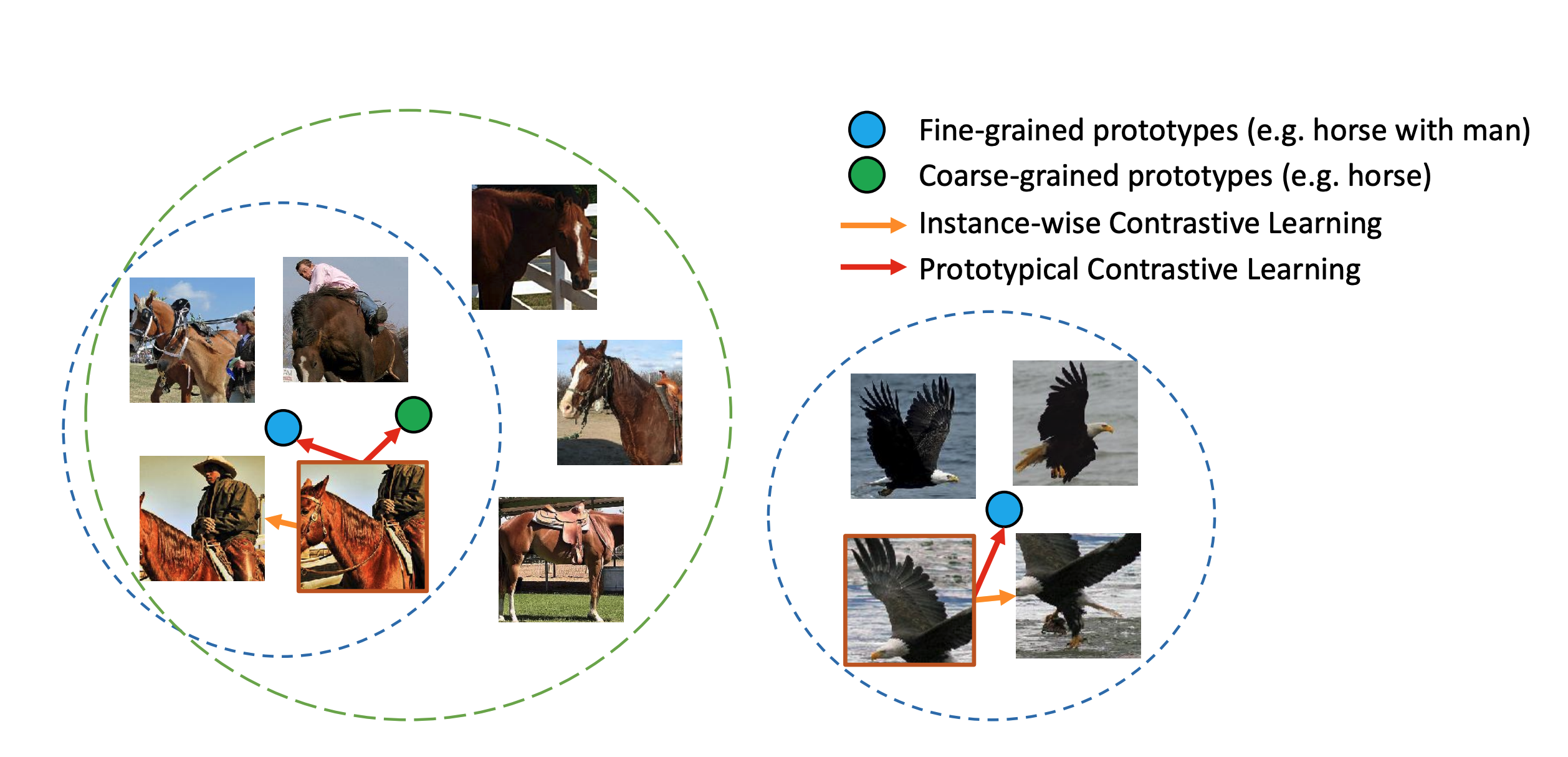
- 2- ペア間の類似度が⾼くても, 負例は負例として扱う
- → **負例ペアにおける類似性についての意味情報は獲得できない **
- (⼤量に負例を扱うと, 類似度が⾼いペアの存在確率が⾼まる)
- 例えば「犬A」と「犬B」があったとしても, 「犬A」ー「犬B」ペアは負例なので互いに遠ざけてしまう
- 1- 低次元の特徴だけで識別できるため, 識別はNNにとって簡単なタスク
-
1つ目の問題点「 **⾼密度な情報をエンコードしているとは⾔い難い **」について
- 考: 例えば, SIFTでの位置合わせを想起すれば, 割と単純な特徴量だけで識別できちゃうんでしょうね
-
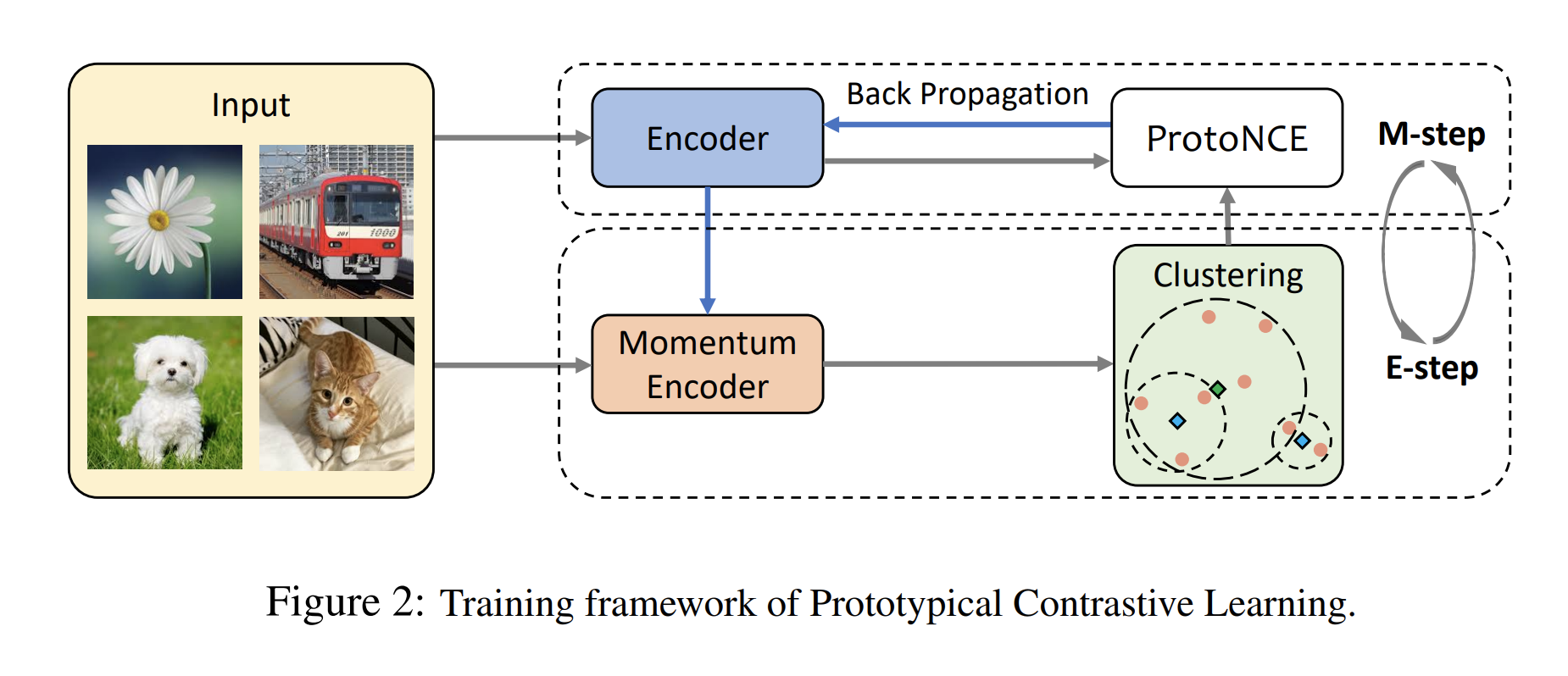
EMアルゴリズムに基づく損失で学習
-
まとめ: クラスタリングを行うので, 特徴空間がいい感じに整理されるっしょっていう話