- 問題点: CLIPは画像全体を用いるため, 物体検出には向かない
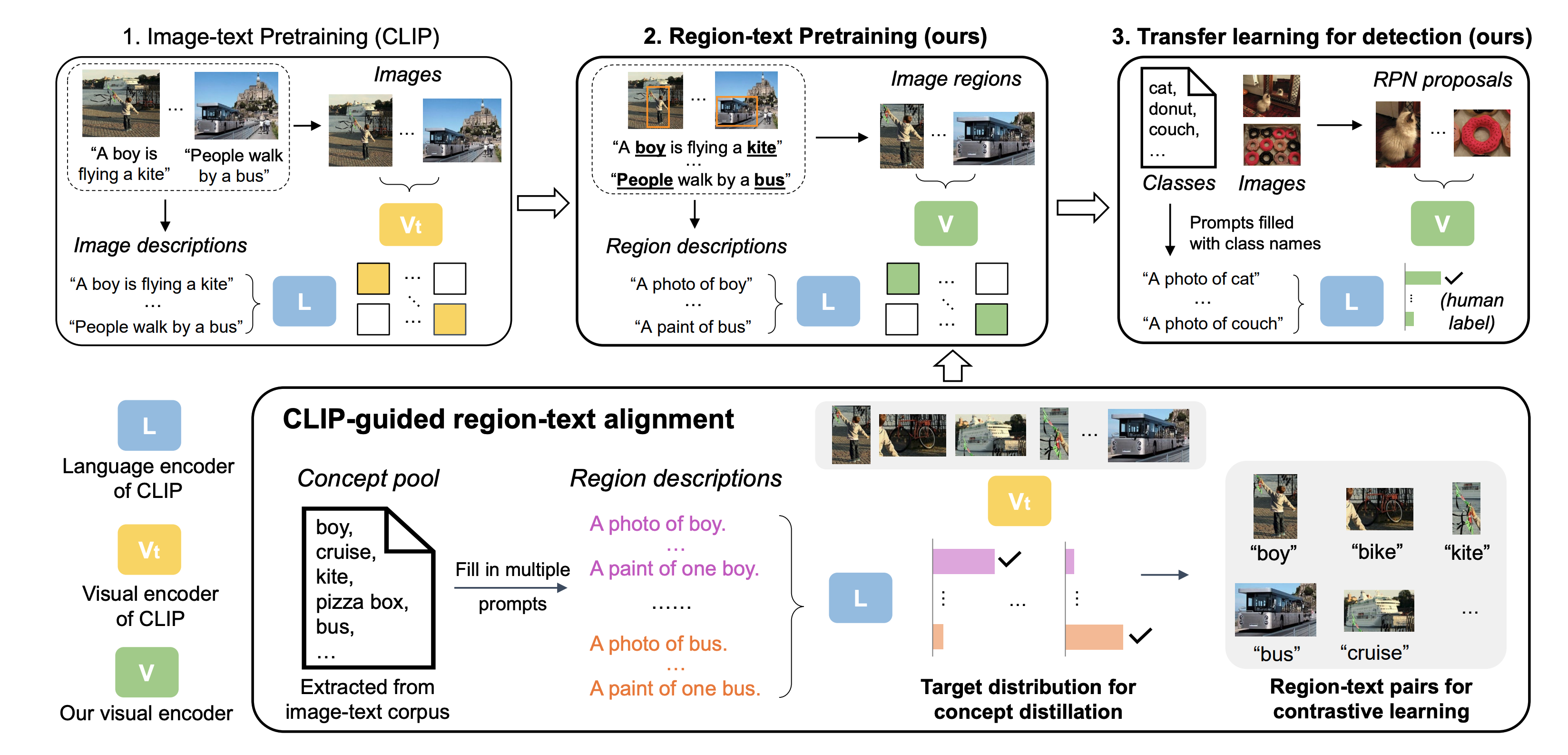
- そこで, 本論文ではCLIPをRegion-text matchingへと拡張した
- CLIPを用いた open-vocabularyな物体検出タスクが行える
- open-vocabulary object detection
- 関連研究としてViLDを挙げている
- CLIPを用いた open-vocabularyな物体検出タスクが行える
- CVPR22
-
流れ
- [RPN](Resion Proposal Network)を用いて候補領域を探す
- RPNはBBOXのみ(ラベルなし)のアノテーションがなされたデータセットで事前学習されたものを使用
- なのでRPNの学習はlossには組み込まれていない
- 指示文から名詞だけを取り出してPrompt Engineeringを行い, それらの集合と検出領域の特徴量の類似度をCLIP同様に計算して学習する
- [RPN](Resion Proposal Network)を用いて候補領域を探す
-
Pretrain
-
検出領域と言語の特徴量ペア $(v,l)$について,
$$L_{cntrst} = \frac{1}{N} \sum_{i} -\log(p(v_i,l_m))$$ -
を対照学習としてのlossとする. ただし,
$$p(v_i,l_m) = \frac {\exp(S(v_i, l_m)/\tau)} {\exp(S(v_i, l_m)/\tau) + \sum_{k\in \mathcal{N}_{r_i}} \exp(S(v_i, l_k)/\tau)}$$ -
また, ネットから収集されたデータでnoisyなので, KL divergenceを用いて知識蒸留を行う
$$L_{dist} = \frac{1}{N} \sum_{i} L_{KL}(q^t_{i}, q_i),$$ -
$L_{cntrst}$を画像全体に拡張したバージョンを $L_{cntrst-img}$とする
-
最終的なlossは以下の通り
$$L = L_{cntrst} + L_{dist} + L_{cntrst-img}.$$
-
-
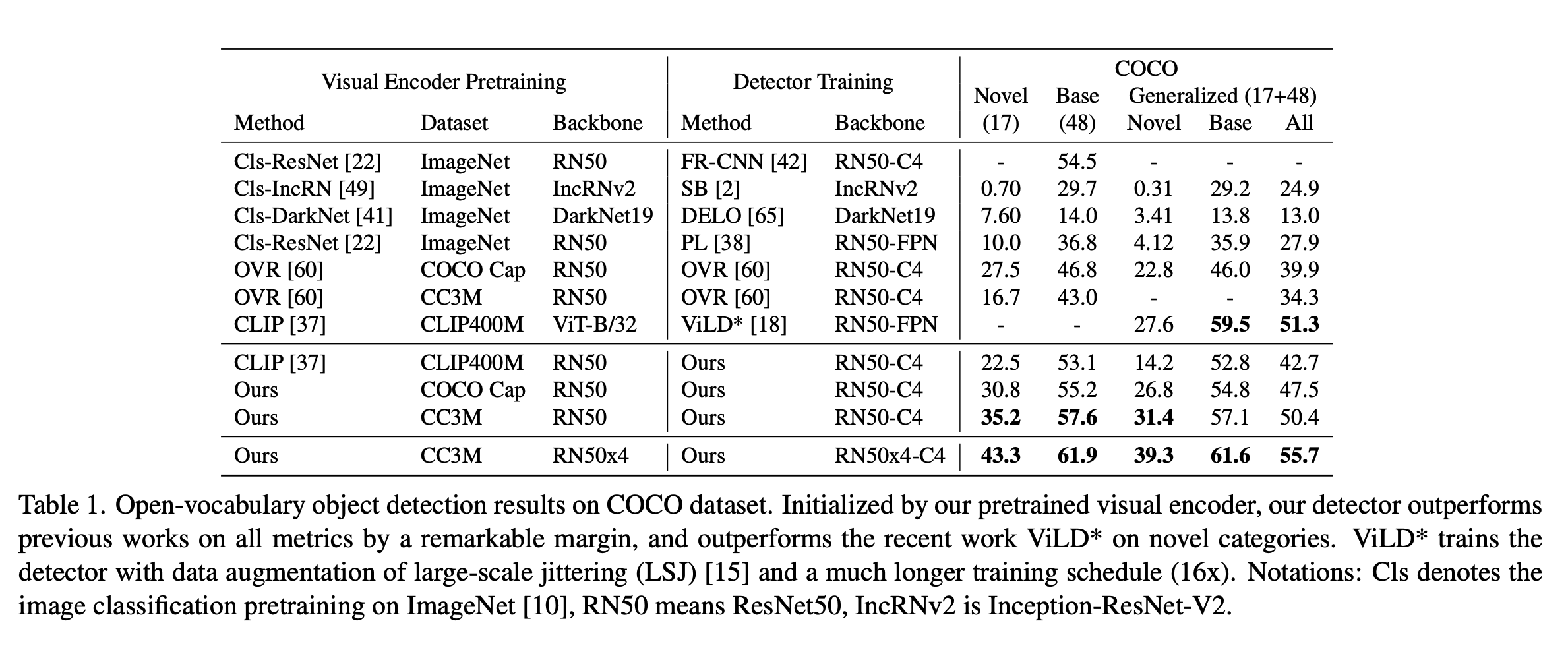
結果
- めっちゃいい感じ

- めっちゃいい感じ