- 適当なページを
curlするとわかるが, scrapboxでは①「俺らが見てるページ」と②「クローラが見てるページ」が違う- ①はServiceWorkerがブラウザ内で動的に生成しているもの
- ②はかなり簡素で, 本文のみがベタ書きされたものであり, 被リンクや1hop-linkなどは特に記述されない
- ここが問題で, ②は内部リンクを削っているにも拘わらず, descriptionとしてリンクのタイトルが列挙してあることがあるため, しょっちゅう変な感じでGoogleに登録される
- 例えば, 被リンクはないが2hopで別ページから飛べるようなページは, 1hop目のページのdescriptionが検索に引っかかって訳のわからん状態になる
- 例: X→Y←Z
- X (内部でYをリンク・被リンクなし)
- Y (本文なし)
- Z (内部でYをリンク)
- YやZのdescriptionにはXの文言が入っているので, 「X」と検索するとYかZのページが検索結果に出る
- またクローラは②を見ているのでYからXへと辿ることができず, Yの被リンク数だけが相対的に高くなる
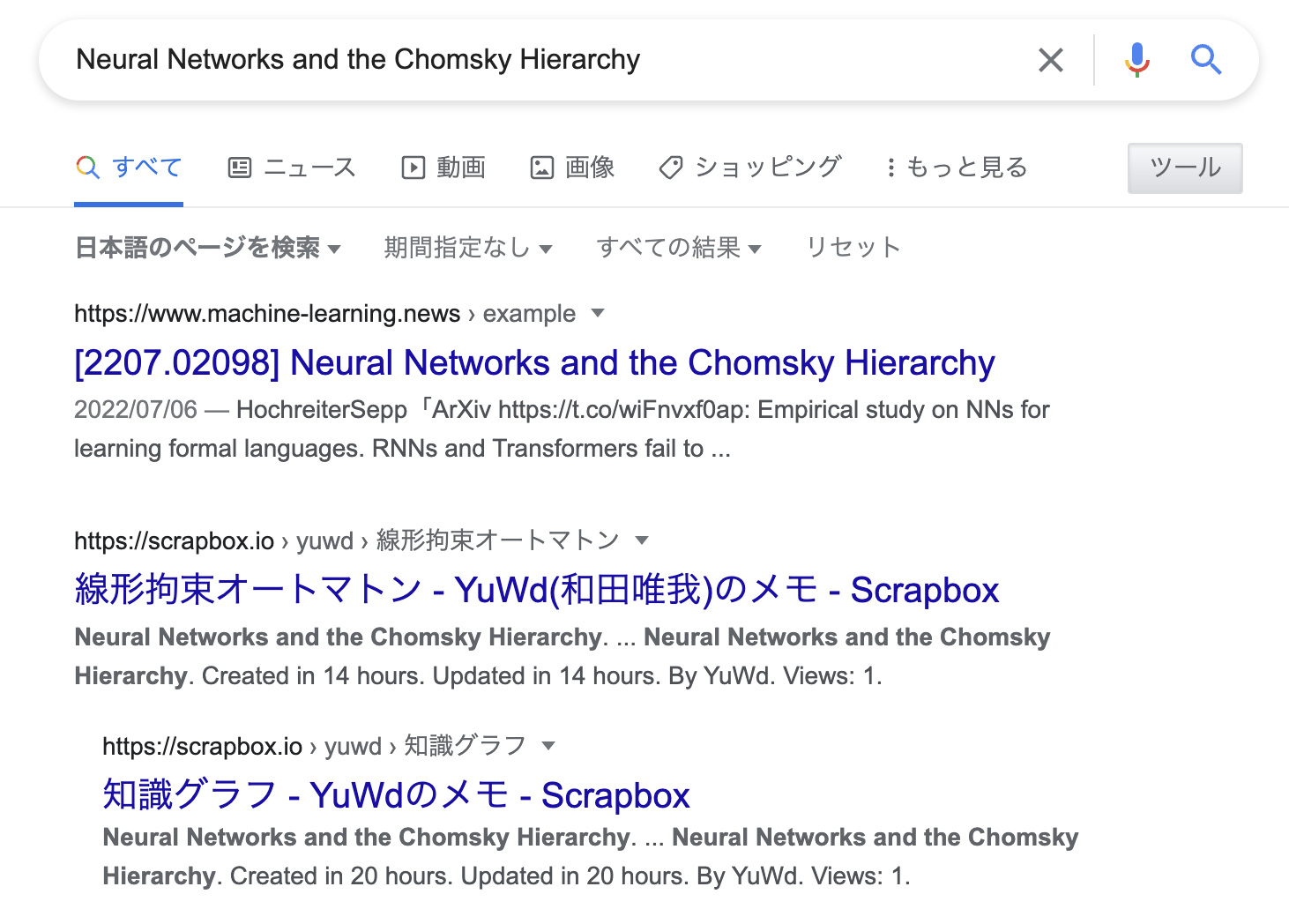
- 具体例
- X = Neural Networks and the Chomsky Hierarchyを検索すると
- こいつの本文中でリンクを貼ったY=線形拘束オートマトンやら
- Y=知識グラフなどのdescriptionが引っかかってカオス状態となる
- 多分, XよりもYのほうが被リンク数が多いのでこっちが引っかかっちゃうのだと思われる
- 内容のボリューム的にはX »» Y = ∅なのだが…
- Y = ∅(本文ゼロ)なのに引っかかっちゃうのが良くないよね
-
なので, 俺らが思っている以上にクローラはページ同士がつながっているように見えてないし, クロールできる半径もかなり限られている
- また, クローラの入り口はページtop(https://scrapbox.io/yuwd )とindexされたページのみなので
- クローラが見つけやすいように目次=リンク集があるとSEO的にはうれしいはず
- ということで, 適当にページ一覧とかpaperとか作って実験中
- ページtopにピン留めしとけば必ずクローラは全ページを巡回できる
-
(もちろん, 用途によってはscrapboxはSEOに強いだろうし, こうした事態もscrapboxの設計思想自体に端を発していると思うが, 俺のように, 調べ物をそのままページ化しておいて, 割かしリンクとしては言及しないような人間には厳しい設計である.別に誰かに見てほしいというわけではないが, そうは言いつつ誰にも見られないというのも悲しきものだ.)
-
目次の生成
|
|