#Computer
#機械学習
[*** — 概要 — ]
-
[** どんなもの?]
- 多層LSTMでML task(Machine-Translation-Task)を解く.
- LSTMを2回通す(encoder/decoder)ことで, T次元ベクトル→固定長の意味ベクトル→T ’ 次元ベクトル と変換することができる. (入力時に語順を逆さにする)
-
[** どういう系譜?先行研究との関係は?]
-
[** 技術や手法のキモは?]
- LSTMによってエンコード
- Beam-Searchによって探索空間をへらす
- 入力時に語順を逆さにする(short term dependency)
-
[** どうやって有効だと検証した?]
- BLEUスコアを測定 (機械翻訳の評価指標)
- 学習時, LSTMの各層(4つ)ごとにGPUを, また別の4つのGPUでsoftmaxの計算を, 計8つのGPUを使用.
-
[** 網羅性と整合性は?]
- ??
-
[** 議論は?]
- 語順を逆さにするってなんだよ
- LSTMで時系列データの問題にすり替えてるのがあんま良くないかもって言われてる(らしい)
-
[** 次に読むべき論文は?]
- Neural Machine Translation by Jointly Learning to Align and Translate (2014)
- Attention is all you need" (2017)
[*** —Note— ]
- BLUEスコアとは
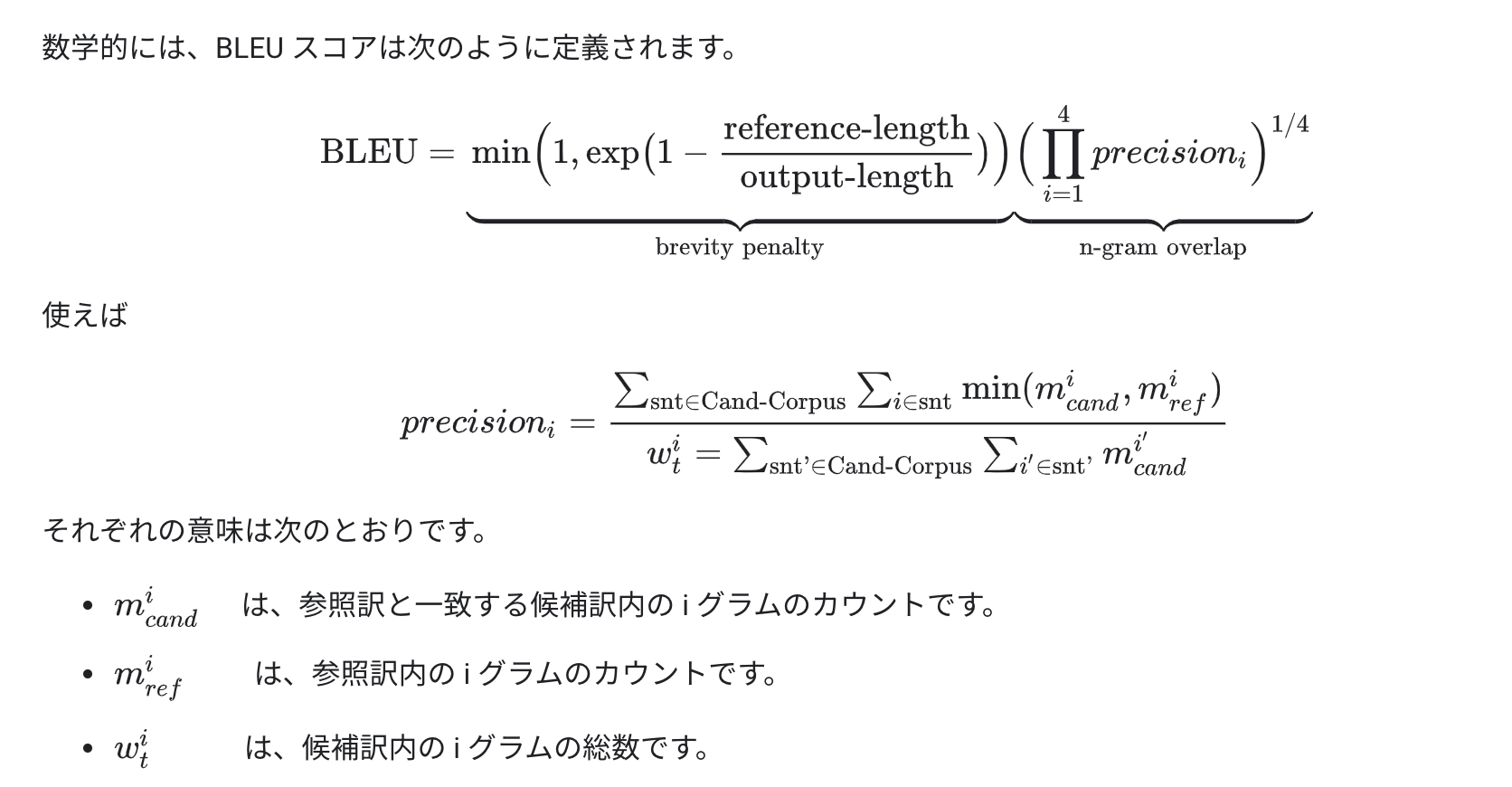
前半は長さに対するペナルティ(参照訳が短すぎるとダメ)
後半は各i-gramごとにprecisionsを計算

BLEU スコアの指標
< 10 ほとんど役に立たない
10~19 主旨を理解するのが困難である
20~29 主旨は明白であるが、文法上の重大なエラーがある
30~40 理解できる、適度な品質の翻訳
40~50 高品質な翻訳
50~60 非常に高品質で、適切かつ流暢な翻訳
60 人が翻訳した場合よりも高品質であることが多い
引用: https://cloud.google.com/translate/automl/docs/evaluate?hl=ja
-
Reversingが有効でないケースはどういうの?
- ???
-
minimal-time-leg
- 翻訳元と翻訳先の対応する単語同士の系列としての最小距離(minimal time lag)が逆順にしたほうが小さくなる
- 逆伝播したときに, 単語同士が近いとうれしい??
-
LSTMs trained on reversed source sentences did much better on long sentences than LSTMs trained on the raw source sentences (see sec. 3.7), which suggests that reversing the input sentences results in LSTMs with better memory utilization.
→ なぜ??どゆこと??
[*** —単語— ]
・penalize
・conventional
・intricate
・perplexity(数学)
・stochastic