はじめに
- Energy Based Modelを用いて画像からscene graphを生成する手法(フレームワーク)を提案
- 既存手法は次のようにクロスエントロピーでscene graphを生成する
$$\log p(SG|I) = \sum_{i \in O} \log p(o_i| I) + \sum_{j \in R} \log p(r_j | I).$$ - このとき, object $O$とrelation $R$が互いに独立に計算されている
- ここが問題で, 本来なら互いに弱い依存性があるはず
- したがって, データがある確率分布 $p_\theta(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})$からサンプリングされていると仮定し, Energy Based Modelに基づいてエネルギー関数 $E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})$を定義し, lossを設計
- 既存手法は次のようにクロスエントロピーでscene graphを生成する
- スライド
Energy-Based Learning for Scene Graph Generation
前提知識
- Energy Based Modelについては以下を見てくだはれ.
- Stochastic Gradient Langevin Dynamicsについては以下を見てくだはれ.
解説
-
流れ
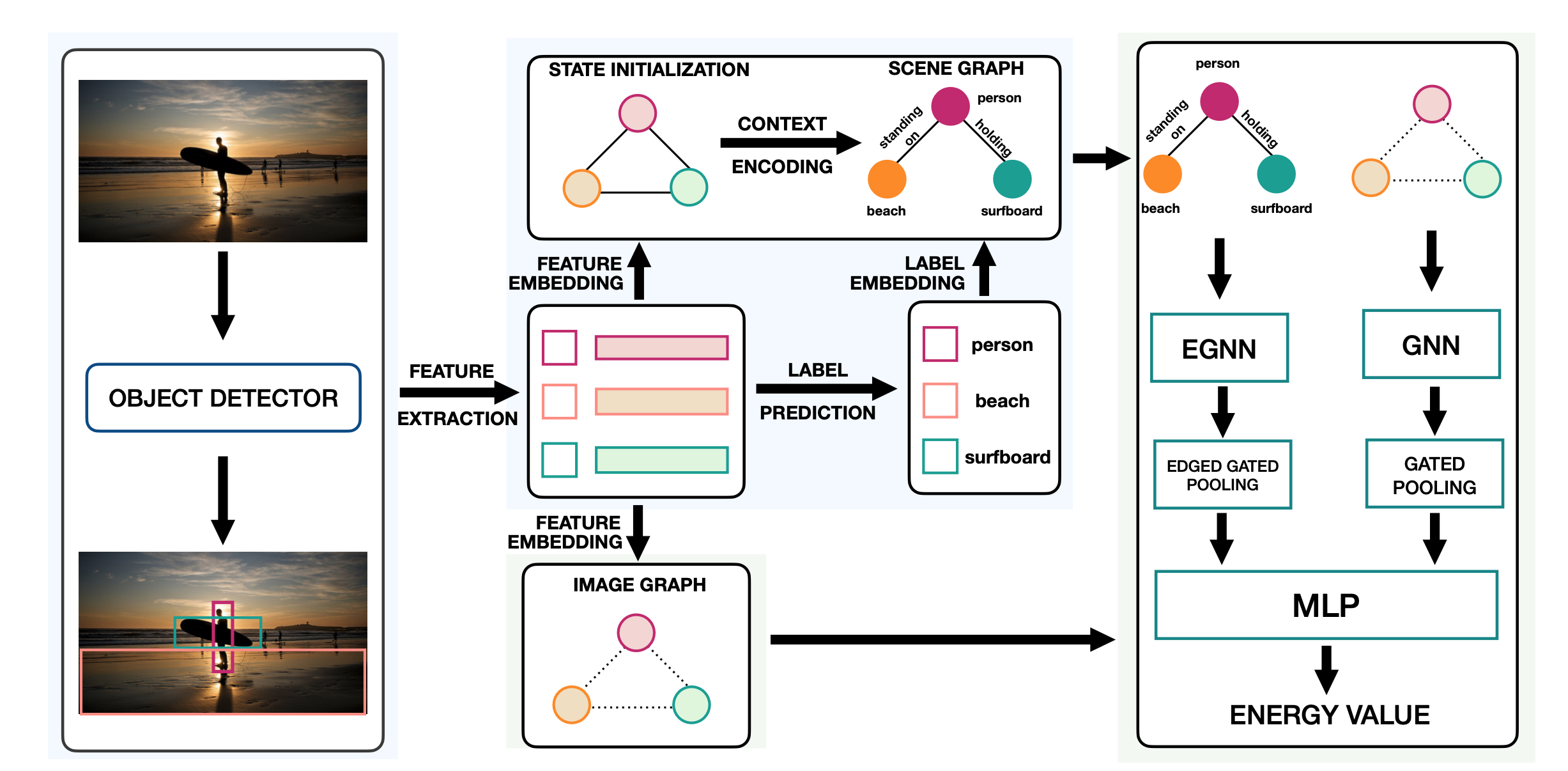
- Faster-RCNNで物体検出
- 各領域をノードとして, Image Graphを $\mathsf{G}_{\mathcal{I}}$,Scene Graph を $\mathsf{G}_{\mathcal{SG}}$とする
- エネルギー関数 $E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})$は以下のようにGNNとEGNN(後述)を通した後に, pooling→concatしてMLPに通したものとする
$$E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}) = \mathrm{MLP} \left\lbrack f(\mathrm{EGNN}(\mathrm{G}_{SG})); g(\mathrm{GNN}(\mathsf{G}_{\mathcal{I}})) \right\rbrack$$ - エネルギー関数 $E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})$について, 以下のようにlossを定義
$$\mathcal{L}_{total} = \lambda_{e}\mathcal{L}_{e} + \lambda_{r}\mathcal{L}_{r} + \lambda_{t}\mathcal{L}_{t},$$
-
lossについて
-
$\mathcal{L}_{e}$について, GTのグラフを $G^+$として以下のように定義
$$\mathcal{L}_{e} = E_{\theta}(\mathsf{G}_{\mathcal{I}}^{+}, \mathsf{G}_{SG}^{+}) - \min_{\mathsf{G}_{SG} \in SG} E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}). $$ -
この式の意味するところは次の通り
- 元の確率分布 $p_\theta(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})$を
$$p_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}) = \frac{\textrm{exp}(-E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}))}{Z_{\theta}} = \frac{\textrm{exp}(f_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}))}{Z_{\theta}}$$ - とすると,
- 元の確率分布 $p_\theta(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})$を
-
$$\mathcal{L}_{e} = -f_{\theta}(\mathsf{G}_{\mathcal{I}}^{+}, \mathsf{G}_{SG}^{+}) + \max_{\mathsf{G}_{SG} \in SG} f_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}). $$
- となり, このlossの最適化(loss↓)は $f_{\theta}(\mathsf{G}_{\mathcal{I}}^{+}, \mathsf{G}_{SG}^{+})$を最大化(↑)して, サンプリングしてきた $f_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})$を最小化するので, trainの値を引き上げ, sampleの値を引き下げることになる
- 第二項の計算はサンプリングが必要なので, Stochastic Gradient Langevin Dynamicsによってサンプリング
$$\mathbf{O}^{\tau+1} = \mathbf{O}^{\tau} - \frac{\lambda}{2} \nabla_{\mathbf{O}}E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}^{\tau}) + \epsilon^{\tau}$$
$$\mathbf{R}^{\tau+1} = \mathbf{R}^{\tau} - \frac{\lambda}{2} \nabla_{\mathbf{R}}E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}^{\tau}) + \epsilon^{\tau}$$
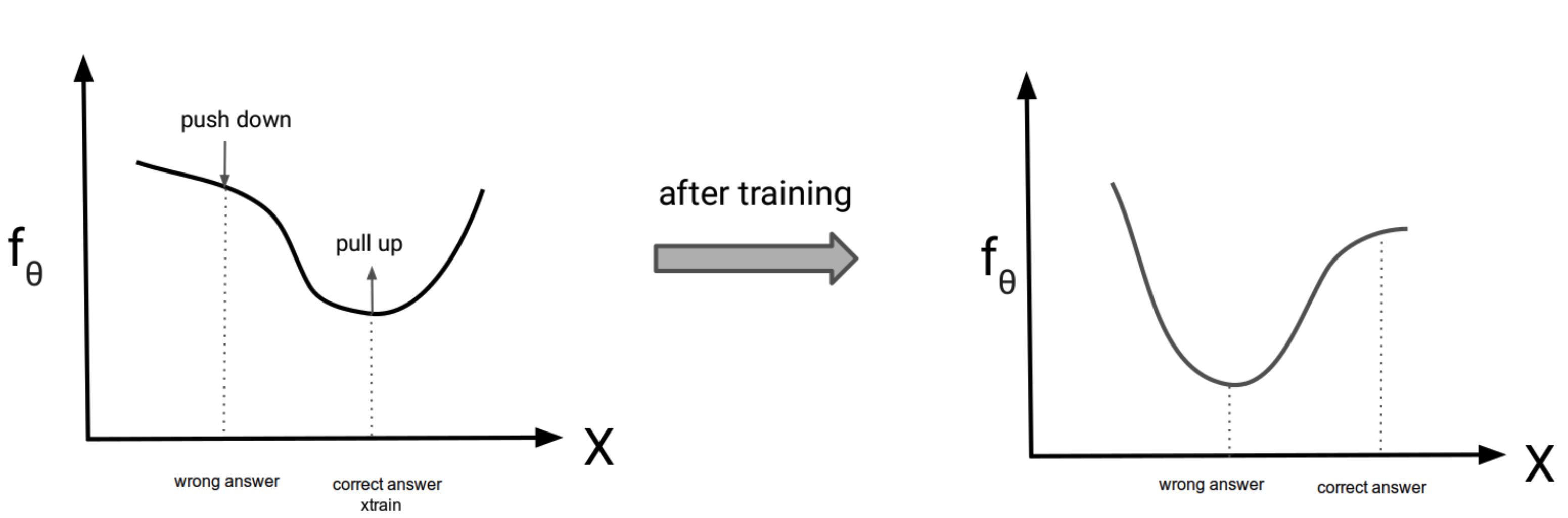
引用: https://deepgenerativemodels.github.io/assets/slides/cs236_lecture11.pdf
-
$\mathcal{L}_{r} $について
- $\mathcal{L}_{e}$だけだと解が爆発してしまったので(そらそうだろ), 正則化項としてのloss $\mathcal{L}_{r}$を追加
$$\mathcal{L}_{r} = E_{\theta}(\mathsf{G}_{\mathcal{I}}^{+}, \mathsf{G}_{SG}^{+})^{2} + E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG})^{2}.$$ -
エネルギー関数について
- 以下のように定義
$$E_{\theta}(\mathsf{G}_{\mathcal{I}}, \mathsf{G}_{SG}) = \mathrm{MLP} \left\lbrack f(\mathrm{EGNN}(\mathrm{G}_{SG})); g(\mathrm{GNN}(\mathsf{G}_{\mathcal{I}})) \right\rbrack$$ - GNNはGated Graph Neural Networks (GG-NNs)を使用
- EGNNは新たに提案された手法
- 以下のように定義
-
EGNN (Edge Graph Neural Network) について
-
ノードにおけるmessage $\mathbf{m}_{i}^{t}$を以下のように定義
$$\mathbf{m}_{i}^{t} = \alpha \underbrace{\mathbf{W}_{nn} \left( \sum_{j \in \mathcal{N}_{i}} \mathbf{n}_{j}^{t-1} \right)}_\text{node to node message} + (1-\alpha) \underbrace{\mathbf{W}_{en} \left( \sum_{j \in \mathcal{N}_{i}} \mathbf{e}_{j \rightarrow i}^{t-1} \right)}_\text{edge to node message}$$ -
エッジにおけるmessage $\mathbf{d}_{i \rightarrow j}^{t}$を以下のように定義
$$\mathbf{d}_{i \rightarrow j}^{t} = \mathbf{W}_{ee}[\mathbf{n}_{i}^{t-1} \mathbin\Vert \mathbf{n}_{j}^{t-1}\rbrack$$ -
それぞれがMessage-Passing方式でGRUに通される
-
-
定量的結果 (VGTree + Energey-Based Loss)
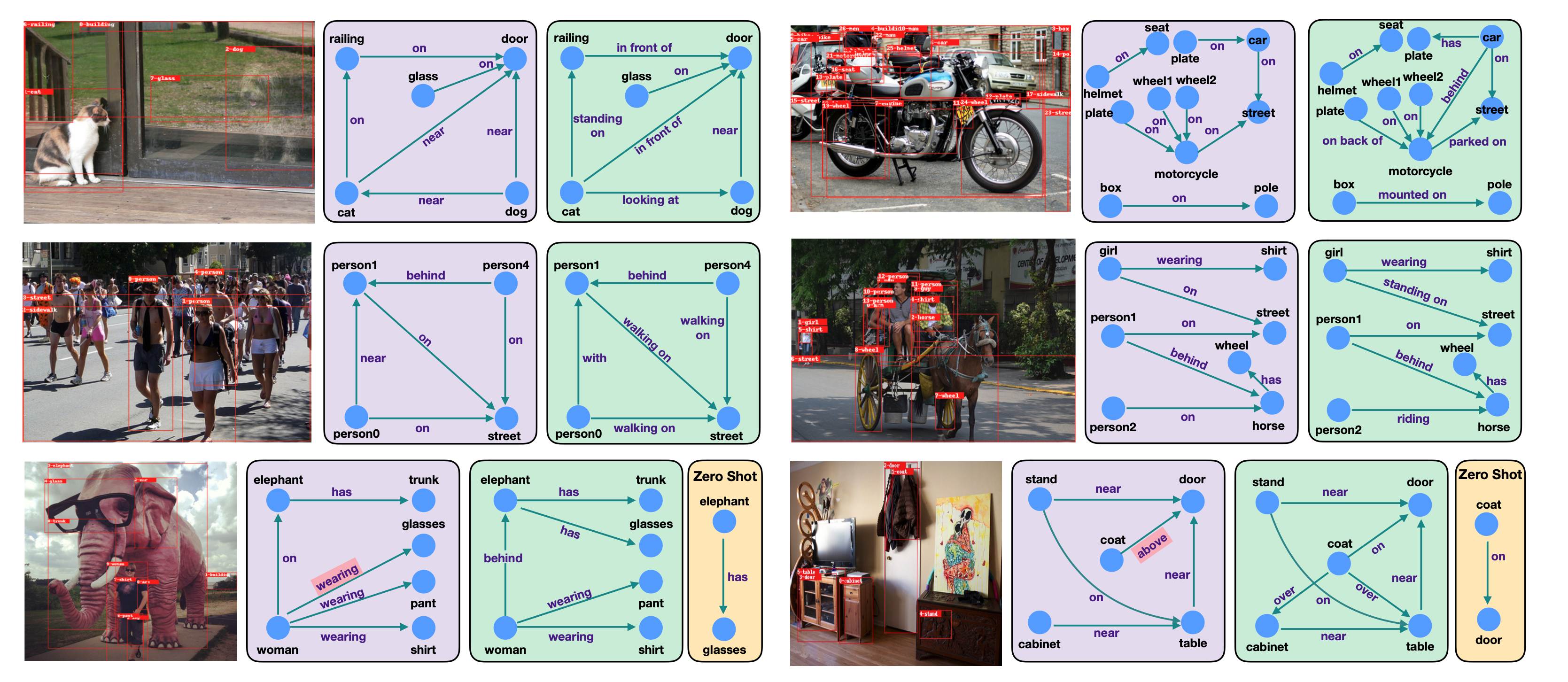
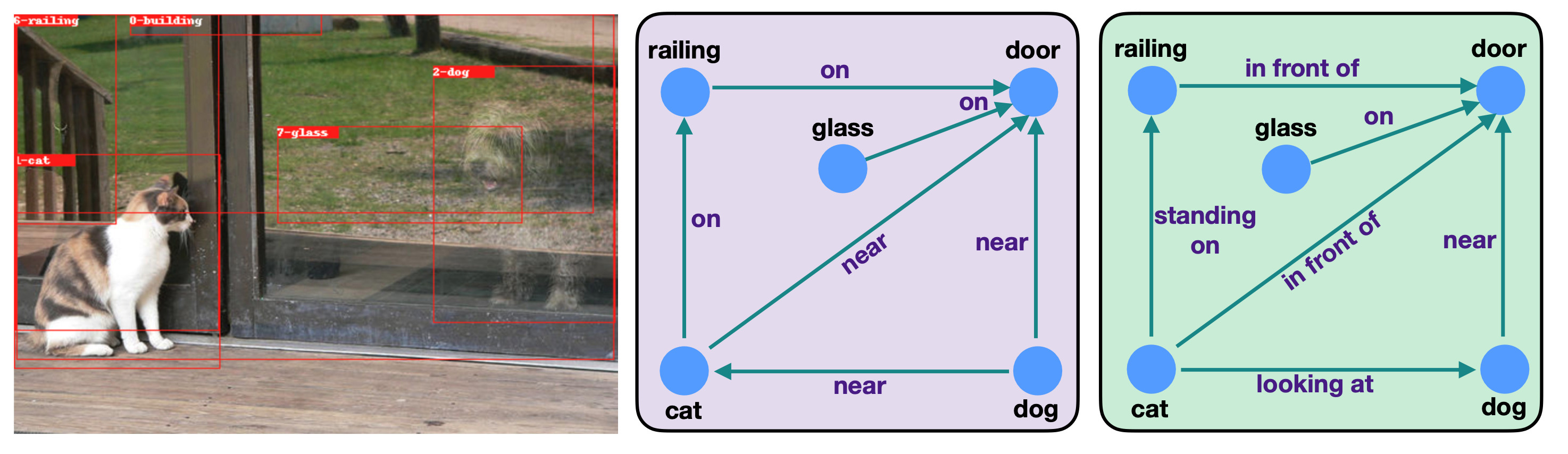
- 一番上の左の結果
- <cat, near, door> → <cat, in front of, door>
- <dog, near, cat> → <cat, looking at, dog>
- となっており, よりinteractiveなrelationが張られている
- 一番上の左の結果